
الكود موجود كله على صفحتي بالجيت هب (تفضل).مكتوب بالبايثون على صيغة ملف جوبيتير(انصحك تنزل الاناكوندا لأنه يشمل الار ستوديو والجوبيتير والسبايدر وبيئات برمجية كثير ).
طبعا اول شي تسويه تنزل البيانات من موقع Kaggle.
طبعا اول شي تسويه تنزل البيانات من موقع Kaggle.

وصف سريع للبيانات
هذي البيانات مأخوذة من دوريات أوروبية مختلفة من 2008 الى 2016 لأكثر من 10 الاف لاعب في أكثر من 25 الف مباراة (بيانات موب ضخمه بس نقدر نقول دسمة 😀 لكن راح تطبق نفس الطرق والمبادئ على بيانات اضخم بكثير) والمتغيرات فيها كثيره لكل لاعب. الي بنسويه اليوم من اسهل الأشياء الي ممكن تسويها والي تقدر تسويه بالعادة أكثر بكثير.
انا بشرح شذرات من الكود واذا عندكم أسئلة ارسلولي:
هذي البيانات مأخوذة من دوريات أوروبية مختلفة من 2008 الى 2016 لأكثر من 10 الاف لاعب في أكثر من 25 الف مباراة (بيانات موب ضخمه بس نقدر نقول دسمة 😀 لكن راح تطبق نفس الطرق والمبادئ على بيانات اضخم بكثير) والمتغيرات فيها كثيره لكل لاعب. الي بنسويه اليوم من اسهل الأشياء الي ممكن تسويها والي تقدر تسويه بالعادة أكثر بكثير.
انا بشرح شذرات من الكود واذا عندكم أسئلة ارسلولي:

وبعد تحميل المكتبات تحتاج ربط قاعدة ال SQL ببيئة البايثون وبعدها ربطها بمكتبة الباندا الي تساعد في ترتيب واعداد البيانات للتحليل الاضافي

نقدر نحسب مقاييس الإحصاء الوصفي (زي المتوسط والمنوال) لكل المتغيرات بإضافة الأمر هذا ()describe. وتقدر تعكس اي data frame بواسطة هالامر ()transpose.
تقدر في مكتبة الباندا تصف الاوامر جنب بعض اذا حاب لإختصار الكود

تنظيف البيانات والتعامل مع البيانات المفقودة
حط في بالك مستحيل تستلم بيانات جاهزة للتحليل. دائما بتلقى بيانات ناقصه واغلاط والبيانات يبيلها شغل لين تصير جاهزه للتحليل. طبع الكود هذا يجمع لك كل البيانات الناقصة لكل متغير.
والحين نحذف البيانات الناقصه:
حط في بالك مستحيل تستلم بيانات جاهزة للتحليل. دائما بتلقى بيانات ناقصه واغلاط والبيانات يبيلها شغل لين تصير جاهزه للتحليل. طبع الكود هذا يجمع لك كل البيانات الناقصة لكل متغير.
والحين نحذف البيانات الناقصه:


توقع "overall_rating" للاعب محدد بأستخدام أرتباط بيرسون
بعد ماخلصنا تنظيف البيانات نقدر نستخدم هالبيانات لتحليلات اعمق. خل نشوف اول خمس صفوف من البيانات بأستخدام امر ()head.

أغلب الوقت بنصير مهتمين ببعض المتغيرات مو كلها. في هذي الحاله، نقدر نختار المتغيرات الي نبي بأستخدام هذي الاوامر (هنا مثلا نبي بس متغيرين):

طبعا تقدر ببساطه تحسب معامل ربط بيرسون بين هالمتغيرين بواسطة سطر واحد بس:
طبعا خل نفترض انك تبي تحسب المعامل بين (overall_rating) و متغيرات اكثر لأنك تبي تشوف وش اكثر واحد فيهم مرتبط بالمتغير الي انت مهتهم فيه. تقدر تستخدم هالكود:

طبعا زي مانشوف اكثر متغير مرتبط ب "overall_rating" هو "ball_control" والمعامل يساوي تقريبا 0.44.
شلون نقدر نقارن بين متغير مهتمين فيه وباقي المتغيرات بطريقه بصريه؟
خل نمر على الاكواد سريعا:

طبعا خلصنا حسبة المعاملات ونبي نرسم.بنستخدم مكتبة matplotlib لبناء دالة عشان نرسم العلاقه بين المتغيرات والمتغير الي مهتمين فيه:

وهاذي هي الرسمه النهائية:
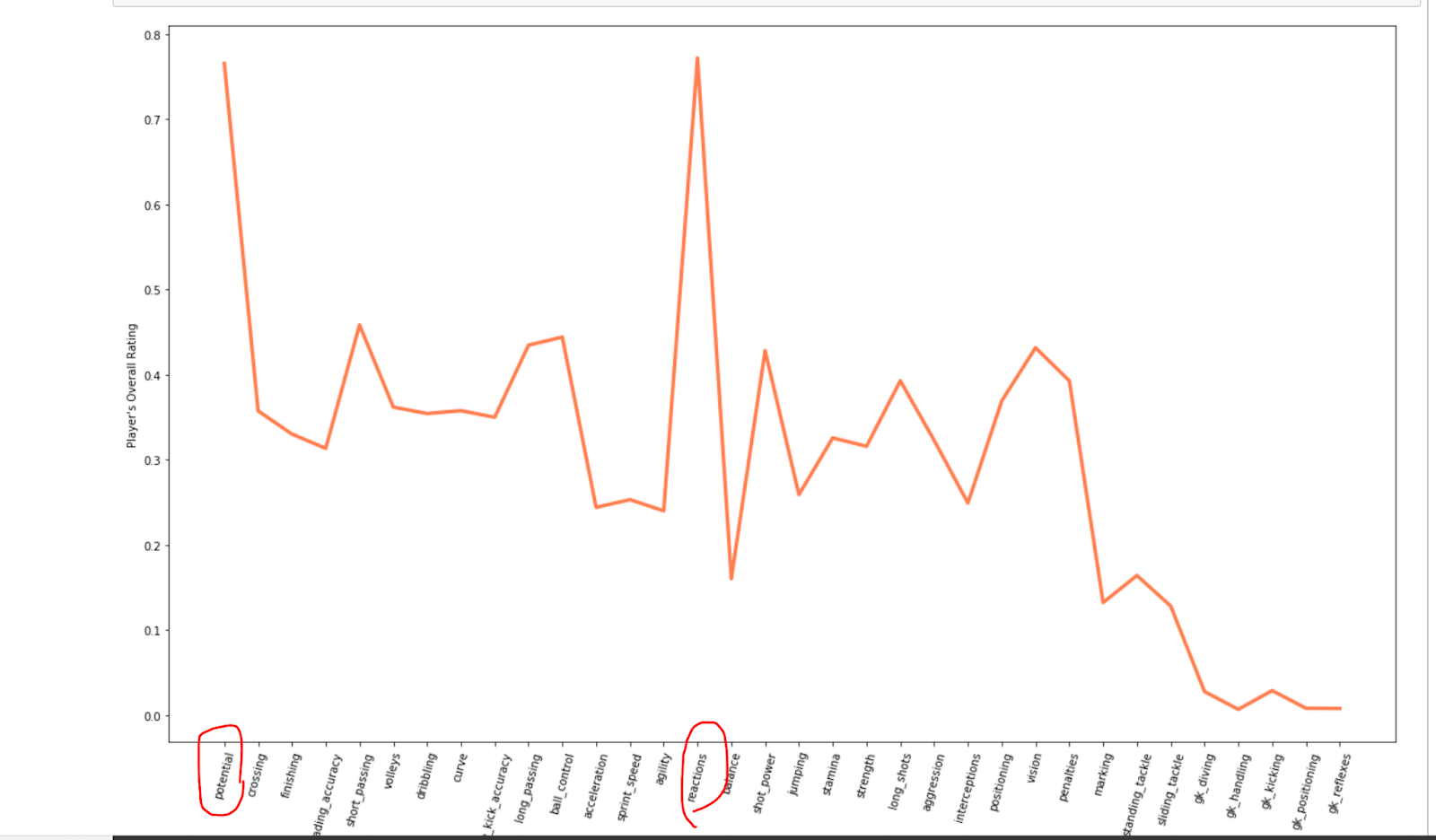
وزي مانشوف النتائج اوضح اذا عرضتها بطريقة بيانيه. اكثر متغيرين ارتباطا بالمتغير الي مهتمين فيه هما potential و reactions.
تجميع اللاعبين الى مجموعات متشابهة بأستخدام k-means
حتى الان استخدمنا الاحصاء الوصفي ومعامل الربط بيرسون لفهم العلاقة بين المتغيرات المختلف. هل نقدر نستفيد من البيانات اكثر؟ هل نستطيع تجميع اللاعبين في مجموعات بناء على تشابههم في متغيرات معينه؟
في هذا المثال بنستخدم خوارزمية ال k-means لتجميع اللاعبين (طبعا نفس الخوارزمية نقدر نستخدمها (supervised or unsupervised). المثال هذا بدون أشراف (unsupervised).
خل نمر على الأكواد. الحين نرتب البيانات للتحليل:

والحين نطبق ال k-means:

طبعا انتهينا بالأربع مجموعات مع عدد اللاعبين بكل مجموعة. لاحظوا ان فية مجموعة أقل من الباقيين وش تتوقعون هم؟؟
خل نرسم البلوت النهائي ( المتغيرات الخمسة والمجموعات الأربعة):

مين تتوقعون من المجموعات الأربع حراس المرمى؟
ليست هناك تعليقات:
إرسال تعليق